Stefan Winkler's Blog
So the year 2016 has already been upon us for three weeks, and one of my resolutions is to write more blog-posts. Let’s see how this turns out…
For one of my customers, I am currently developing a GEF/Draw2D-based editor. I chose GEF 3.x instead of GEF4 for the implementation mainly for two reasons:
- The target platform of my client as of now is Eclipse Luna and I am unsure if I would have been able to get GEF4 to work on Luna (there are other EMF features in the target platform used by different components, so I am not very flexible with respect to versions in the EMF field)
- Due to its maturity, there seems to be more documentation out there for GEF 3.x than there is for GEF4. For example, I have found the Kindle version of The Eclipse Graphical Editing Framework on Amazon. While this book does not contain the answer to all obstacles I came over, it contains a lot of answers and explanations, and I can recommend it as a good reference and tutorial.
In the next few blog posts, I will point out some of these obstacles which I were not able to find a solution right away, and I hope that by writing about them, and how I solved them, I will help others to find answers to similar issues faster.
So here goes–something simple to start off:
Untyped EditPart members
Obstacle:
Well—not really an "obstacle", but I found it quite annoying that org.eclipse.gef.editparts.AbstractGraphicalEditPart returns general types for getModel(), getFigure(), and getParent().
- Details
- Category: Eclipse
At EclipseCon NA 2014 Project Oomph has created some buzz. Project Oomph by Eike and Ed is an attempt of making contributing to an Eclipse project dead easy by providing an automated setup process for each project.
Setting up a workspace with the correct tooling, target platform, imported projects and baseline is a matter of just downloading and starting a setup application, selecting the desired project, clicking ok, and getting some coffee (the latter is optional and not included in the setup tool package ...). Read more here.
For some time now, I have been looking for an easy way to manage my own bunch of Eclipse installations. For example, I have one IDE for CDO development, one IDE for one customer who works with a Servets-based Tomcat application, one IDE for another customer who implements an internal IDE for C development, one IDE for my own sandbox-projects (which lead to stuff like CDO-Xtext), and in my free time, I am typesetting music from time to time using the Eclipse-based Lilypond IDE Elysium.
The problem is that every time a new release (or milestone) comes out, I have to update all of these installations, which has been (until now) quite cumbersome, because automatically updating the installations while preserving the correct set of needed plugins and features just did not work well.
But with project Oomph, I have started to create setup models for all my different installations and it really works well while being simple at the same time: installations based on Project Oomph will update installed features as updates become available while keeping the set of features intact. (Note: it is actually the p2 director that does all the magic, and there is other means to control the p2 director to achieve my requirements of installing a workspace with a given set of features. It is just that Project Oomph provides a very nice and clean way to model the desired results).
This guide describes how to set up a workspace for the setup model tooling and how to get started in general.
So after setting up the workspace, create a new empty project and create a new empty setup model. The first thing to add is a p2 director task. Under this task, you can specify the Installation Units (IUs) to install into your IDE and the repositories to install from.
Unfortunately, there is no way to browse and select IUs from the repositories directly. But I have already opened an enhancement request for this. Until this is implemented, you can, e.g., work with the b3 tooling and create a temporary aggregation model, add validation repositories, and use the repository browser to identify and copy-paste IU IDs.
When the p2 task is configured, you can set up any other tasks you need (e.g., clone git repositories, import projects, configure a baseline, adjust preferences, etc.).
To use you setup model, just copy it into the main directory of the Setup application (under MacOS X you have to use Setup.app/Contents/MacOS/). When you start the setup tool next time, your own models are listed at the top of the projects list and you can install them from there.
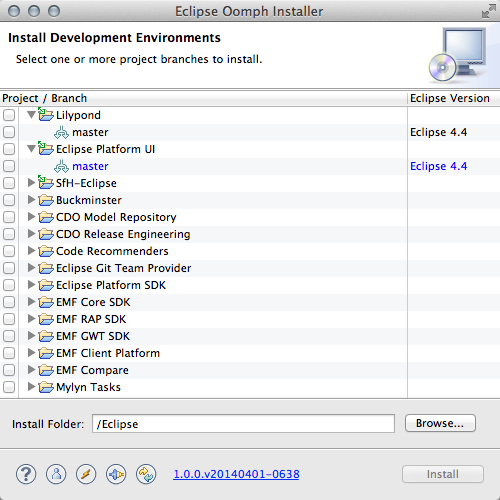
Also, by creating or modifying your personalized setup model addition (on Mac, this is located under ~/.eclipse/org.eclipse.emf.cdo.releng.setup/setup-eclipse.xmi), you can set your favorite preferences or add your favorite features once in there and have them automatically applied to all of your installations. For example, for Mac OS X, I very much like the Mac OS X workspace badge plugin. So I included it in my setup-eclipse.xmi and at the same time set its configuration option to the name of the installed workspace:
Instead of editing the setup-eclipse.xmi by hand, you can also use these two buttons:

(1) will open the setup-eclipse.xmi in the setup model editor and (2) will open the preferences dialog and add all changes you make to the model.
To give an example for a more complex setup model, I have followed the instructions on the Eclipse Platform UI workspace setup guide. This guide lists several steps to setup and configure your workspace so you can contribute to the Platform UI project. Instead of following this guide, you can now use this setup model and the Oomph installer to get started in no time.
(Disclaimer: I have created this setup model just for my own needs. Please consider this unofficial and unmaintained for now. In particular, only the setup for master branch development is currently available. But if someone wants to pick up this model and create an official version, feel free to go ahead and do so!)
Summary: Oomph is cool. It makes installation and maintenance of eclipse installations a breeze.
The Oomph project is currently located in the CDO.releng component but is currently proposed as a separate, Eclipse Tools project. If all goes well, the easter bunny will bring us this project and hopefully a lot more useful features :-).
- Details
- Category: Eclipse
Sometimes it's the small things that make life a lot easier.
In my daily work, I found myself often writing code in the Debug perspective. When I noticed, I asked myself: Why?! Then I analyzed myself and found out that the UI element for switching back to the Plug-In Development perspective (which is the perspective I work in 90% of the time) after debugging something was just too hard to reach. I'd have to move the mouse cursor the long way over to the upper right corner of the screen, look for the Plug-In Development perspective button between all those open perspectives, and click it.
Ok, there is ⌘+3 (or CTRL+3 for non-Mac users) which you can use as well. But then you have to type a few letters to search and sometimes you intuitively select the wrong result etc. So, nah! – that's not it either.
But then it occurred to me: why not create a custom shortcut? I was in doubt whether you can assign a shortcut to a specific perspective, so I looked in the preferences and voilà:

So I quickly assigned ⇧+⌘+1 to the Plug-In Development perspective and ⇧+⌘+2 to the Debug perspective and now I can switch between both at light speed. I haven't thought about this earlier – I don't know why.
So the lesson learned today is: if you find yourself working inefficiently, step back for a second, analyze yourself and try to find a solution to fix it. Maybe the solution you need is only a preference setting away.
And I hope, the idea of assigning shortcuts to perspectives helps someone else out there ...
- Details
- Category: Eclipse
One challenge in my daily work with my email is dealing with automated mails from Hudson or Bugzilla. As I am involved with several customer projects, I cannot keep track of all the Eclipse committer-related mail during the day.
As I am using GMail, I have become used to the mail filtering mechanism GMail offers to make email sent from Bugzilla or Hudson bypass the inbox and land in a separate IMAP folder (GMail uses a label metaphor, but when accessing mails via IMAP, GMail labels are mapped to IMAP folders).
Until recently, however, there was one problem, which I had not solved for months. As perhaps a lot of people do, I am not only receiving Bugzilla notifications related to bugs for which I am reporter, assignee, or on the CC list, but I also watch other Bugzilla accounts; most notably I, follow the
- Details
- Category: Eclipse
Read more: Separating the Wheat from the Chaff — Or: How to Sort Bugzilla Mails